—这是一篇认真的题解—
洛谷题号:P2725
USACO 3.1节 Stamps
这道题目是一道动态规划题目,本来一开始想用记忆化搜索做,但是这样的话空间复杂度太大,最后不得不改变想法,找到了一个能用动态规划的思路。
第一次代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #include<iostream> #include<algorithm> #include<cstring> #include<vector> using namespace std; bool available[2000005]; int postticket, single, single_value[55]; void cal(int cursingle, int curpos,int cursum){ if (curpos == postticket + 1 || cursingle == single + 1)return; for (int i = cursingle; i <= single; i++){ available[cursum + single_value[i]] = true; cal(i, curpos + 1, cursum + single_value[i]); cal(i + 1, curpos, cursum); } } int main(){ ios::sync_with_stdio(false); available[0] = true; cin >> postticket >> single; for (int i = 1; i <= single; i++){ cin >> single_value[i]; } cal(1, 1, 0); int x = 0; while (available[x])x++; cout << x - 1; } |
我的第一个想法是用搜索去做,把每一个空缺的位置填充为不同面值的邮票,邮票的面值遵从单调递增的原则。空缺的位置可以不填满,这样就是如上的代码。但是这样做效率极差,才63分:8/13AC,5/13TLE。超时了,程序连记忆化都没有做。我尝试加上记忆化,但是根据数据范围,如果开这么大的数组一定会超内存。所以这条路子走不通。
第二次代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include<iostream> #include<algorithm> #include<cstring> #include<vector> using namespace std; int available[2100005]; int postticket, single, single_value[55]; int main(){ ios::sync_with_stdio(false); memset(available, 0x7f, sizeof(available)); available[0] = 0; cin >> postticket >> single; for (int i = 1; i <= single; i++){ cin >> single_value[i]; } sort(single_value + 1, single_value + single + 1); //dp for (int k = 1; k <= single; k++){//面值种类 for (int x = 0; available[x] <= postticket; x++){//可用金额 for (int n = 1; available[x] + n <= postticket; n++){//面值张数 if (available[x + single_value[k] * n] > available[x] + n){ available[x + single_value[k] * n] = available[x] + n; } } } } int x = 0; while (available[x]<=postticket)x++; cout << x - 1; } |
我是怎么想到这么做的呢?请看第一次代码的第25行,这行代码的作用是,查找从1开始连续的邮资最大值。既然最后程序统计时每次都要查找一遍,我能不能不把全部的结果算出来,而是从1开始逐渐递推,借助前面的结果,一个一个往后算呢?这就是动态规划的典型思想……(好像说了一堆废话)由此,我想到以邮票的面值种类、当前可用金额,当前面值可用张数作为动态规划的状态,当前所用邮票张数作为状态中存储的值进行迭代,只要发现一个金额要用的邮票张数比原来少就更新为少的邮票张数。最后仍旧从1向后统计,只要邮票张数小于最大张数就可以。要注意的是在进行DP之前必须要把邮票面值升序排序,这样才可以确保小额面值的邮票能够在小额邮费的邮件上体现出来。升序排序的问题我个人也解释不太清楚,想不明白这个问题的童鞋可以把不排序的数据手动执行一下,就会有感觉了。整体动态规划的思路,好像说的也不是特别清楚,大家可以自己看代码。这个程序也存在问题,仍旧有3个点TLE,79分,但是时间差得不多,并且算出的结果也是正确的,于是我就对这个程序再进行了小小的改进。
第三次代码:(AC)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include<iostream> #include<algorithm> #include<cstring> #include<vector> using namespace std; int available[2100005]; int postticket, single, single_value[55]; int main(){ ios::sync_with_stdio(false); memset(available, 0x7f, sizeof(available)); available[0] = 0; cin >> postticket >> single; for (int i = 1; i <= single; i++){ cin >> single_value[i]; } sort(single_value + 1, single_value + single + 1); //dp for (int k = 1; k <= single; k++){//面值种类 for (int x = 0; available[x] <= postticket; x++){//可用金额 for (int n = 1; available[x] + n <= postticket; n++){//面值张数 if (available[x + single_value[k] * n] > available[x] + n){ available[x + single_value[k] * n] = available[x] + n; } else break; } } } int x = 0; while (available[x]<=postticket)x++; cout << x - 1; } |
先上洛谷AC截图:
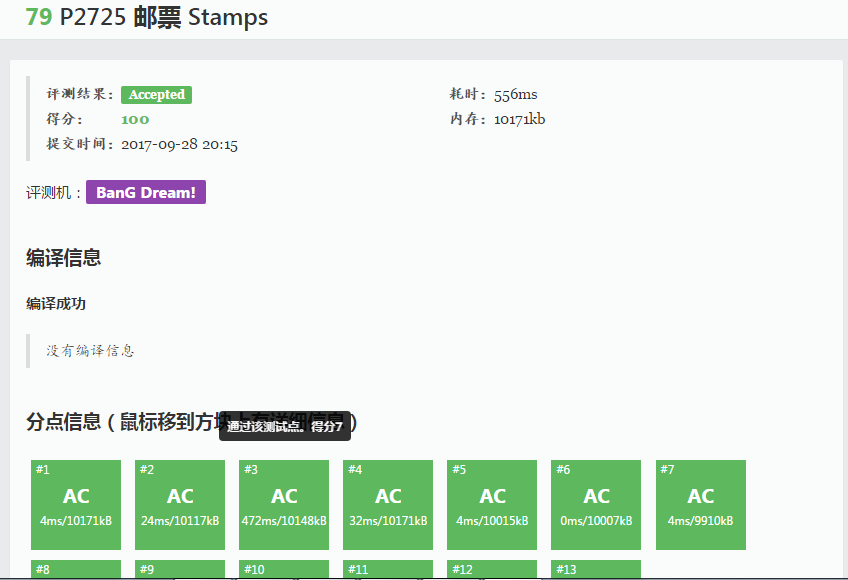

可以看出第三版的区别和第二版仅仅差在了第三版24行的else break语句上。它的意思是,只要检测到当前面值目前使用次数与上一递推基粘贴邮票个数的和大于当前邮票面值总额所对应的邮票总张数,就不再增加当前面值邮票的个数,直接终止当前循环。这个语句为什么能够发挥作用呢?“当前面值目前使用次数a与上一递推基粘贴邮票个数的和b大于当前邮票面值总额所对应的邮票总张数c”意味着当前状态下当前面值邮票后面的邮票总额都由前面这个较小的c推出,因为要取最小值,所以c不会被更新为a+b,如果再把a扩大,那么后面做的就全都是无用功了,而且这个无用功还占了很大一部分。这也就是多了这一行语句就能AC的原因。
—题解完毕—
PS:写的感觉挺不通顺的,理解好的同学能看懂就看看,看不懂就直接看看代码好了。我保证代码一定是对的。
PPPS:开心,头一个自己写的比较难的DP(也算是把递归改成递推,这个思路还算比较清晰),改了好多遍才A,给自己鼓个掌,233333,哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈。OI大神轻喷
PPPPPPS:几天之后自己再来看都不一定能看懂。
有哪位童鞋对我的修辞或者代码(整篇文章)有修改的高见,请留言告诉我,我一定会修改错误的。
—刚刚看题解发现这道题是个完全背包,傻不拉唧的写了两个钟头,还写了半天这么垃圾的题解—我错了—-