开始接触计算几何啦!!!
CG2017 PA1-1 Convex Hull (凸包)
Description (描述)
After learning Chapter 1, you must have mastered the convex hull very well. Yes, convex hull is at the kernel of computational geometry and serves as a fundamental geometric structure. That’s why you are asked to implement such an algorithm as your first programming assignments.
Specifically, given a set of points in the plane, please construct the convex hull and output an encoded description of all the extreme points.
经过了第一章的学习,想必你对于凸包的认识已经非常深刻。是的,凸包是计算几何的核心问题,也是一种基础性的几何结构。因此你的第一项编程任务,就是来实现这样的一个算法。
具体地,对于平面上的任意一组点,请构造出对应的凸包,并在经过编码转换之后输出所有极点的信息。
Input (输入)
The first line is an integer n > 0, i.e., the total number of input points.
The k-th of the following n lines gives the k-th point:
pk = (xk, yk), k = 1, 2, …, n
Both xk and yk here are integers and they are delimited by a space.
第一行是一个正整数首行为一个正整数n > 0,即输入点的总数。
随后n行中的第k行给出第k个点:
pk = (xk, yk), k = 1, 2, …, n
这里,xk与yk均为整数,且二者之间以空格分隔。
Output (输出)
Let { s1, s2, …, sh } be the indices of all the extreme points, h ≤ n. Output the following integer as your solution:
( s1 * s2 * s3 * … * sh * h ) mod (n + 1)
若 { s1, s2, …, sh } 为所有极点的编号, h ≤ n,则作为你的解答,请输出以下整数:
( s1 * s2 * s3 * … * sh * h ) mod (n + 1)
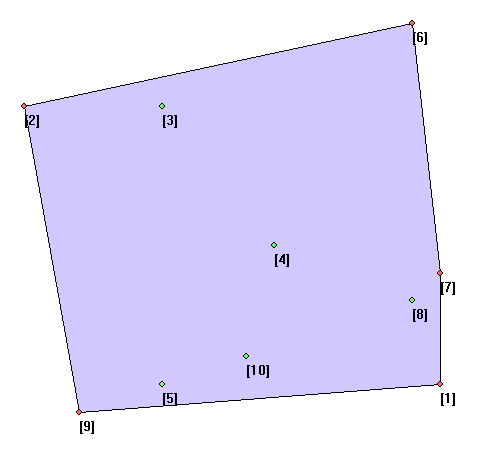
Sample Input (输入样例)
10
7 9
-8 -1
-3 -1
1 4
-3 9
6 -4
7 5
6 6
-6 10
0 8

Sample Output (输出样例)
7 // ( 9 x 2 x 6 x 7 x 1 x 5 ) % (10 + 1)
Limitation (限制)
- 3 ≤ n ≤ 10^5
- Each coordinate of the points is an integer from (-10^5, 10^5). There are no duplicated points. Each point is selected uniformly randomly in (-10^5, 10^5) x (-10^5, 10^5).
- All points on extreme edges are regarded as extreme points and hence should be included in your solution.
- Time Limit: 2 sec
- Space Limit: 512 MB
- 3 ≤ n ≤ 10^5
- 所有点的坐标均为范围(-10^5, 10^5)内的整数,且没有重合点。每个点在(-10^5, 10^5) x (-10^5, 10^5)范围内均匀随机选取
- 极边上的所有点均被视作极点,故在输出时亦不得遗漏
- 时间限制:2 sec
- 空间限制:512 MB
Hint (提示)
Use the CH algorithms presented in the lectures.
课程中讲解过的凸包算法
分数:92.5
使用Graham Scan算法。凸包板子题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | #include<iostream> #include<string> #include<algorithm> #include<vector> using namespace std; struct point { long long x, y, id; point() :x(0), y(0) {} point(long long x, long long y) :x(x), y(y) {} bool operator ==(const point& p) const { return x == p.x && y == p.y; } }PP; //PP: Polar Point vector<point> points; long long area2(point p, point q, point s) { /* |p.x p.y 1| |q.x q.y 1| == 2*DirectedTriangleArea(p,q,s) |s.x s.y 1| */ return p.x * q.y - s.x * q.y + q.x * s.y - q.x * p.y + s.x * p.y - p.x * s.y; } bool toLeftTest(point p, point q, point s) { //When return value large than 0, S is on the left side of ray PQ return area2(p, q, s) > 0; } bool toLeftTest2(point p, point q, point s) { //When return value large than 0, S is on the left side of ray PQ return area2(p, q, s) >= 0; } bool cmp(const point& p1, const point& p2) { // Sort according to polar angle return PP == p1 || !(PP == p2) && toLeftTest(PP, p1, p2); } point LTL(vector<point>& points) { //Lowest then leftmost point ltl = points[0]; for (int i = 1; i < points.size(); i++) { if (points[i].y < ltl.y || points[i].y == ltl.y && points[i].x < ltl.x) ltl = points[i]; } return ltl; } vector<point> grahamScan() { PP = LTL(points); sort(points.begin(), points.end(), cmp); vector<point> S, T; S.push_back(points[0]); S.push_back(points[1]); for (int i = points.size() - 1; i > 1; i--)T.push_back(points[i]); while (!T.empty()) { if (toLeftTest2(S[S.size() - 2], S[S.size() - 1], T[T.size() - 1])) { S.push_back(T[T.size() - 1]); T.pop_back(); } else S.pop_back(); } return S; } int main() { ios::sync_with_stdio(false); long long n; cin >> n; for (int i = 1; i <= n; i++) { point tmp; cin >> tmp.x >> tmp.y; tmp.id = i; points.push_back(tmp); } vector<point> result; if (points.size() > 2)result = grahamScan(); else result = points; long long res = 1; for (int i = 0; i < result.size(); i++) { //cout << result[i].id << endl;//debug res = ((res % (n + 1)) * (result[i].id % (n + 1))) % (n + 1); } res = ((res % (n + 1)) * (result.size() % (n + 1))) % (n + 1); cout << res; } |